Search and Generative AI Experiment in the Philippines
What I learned in SEO from playing with Python and generative AI so far.
I enjoyed trying out OpenAI's API when I was finally able to understand how to get a generation using Python. I started experimenting with it even before the GPT-4 model came out.
I remember being so excited about the new, more expensive model. It was supposed to be more powerful and more robust. I remember barely being able to put together a "Search-Engine Optimized Blog Outline Generator" using Flask. I remember feeling nervous about showing it to some coworkers, as I am not really a developer.

Little did I know that this experience would provide me with the motivation to keep on learning and experimenting with Python. But enough of reminiscing. I called you all here today to share some insights I have from some of the other generative AI experiments I did with search.
Note that these are personal projects, and I did spend a bit for API credits, but I'd say it was worth it. Since I made the search-engine optimized blog outline generator, I thought of taking it a step further: how about a draft generator?
I was able to make one with a slightly better UI, thanks to Streamlit. Another major difference was that I was able to incorporate "new" information that is passed to the LLM before it started writing. I did that by creating a function for searching the topic on DuckDuckGo and then scraping it using Playwright."
from duckduckgo_search import DDGS
def search_duckduckgo(query, search_type):
region = 'en-ph'
safesearch= 'Off'
timelimit='y'
max_results = 5
with DDGS() as ddgs:
results = []
if search_type == 'text':
for r in ddgs.text(query, region=region, safesearch=safesearch, timelimit=timelimit, max_results=max_results):
results.append(r)
elif search_type == 'news':
ddgs_news_gen = ddgs.news(query, region=region, safesearch=safesearch, timelimit='m', max_results=max_results)
for r in ddgs_news_gen:
results.append(r)
else:
raise ValueError("Invalid search_type specified. Use 'text' or 'news'.")
return resultsA basic function for getting links from DuckDuckGo
So what was the output? The Streamlit app that I made was able to provide a barely passable draft of any topic (even in Filipino). I had several templated prompts based on my needs: do I need longform or do I just need a quick blog post?
Why is this distinction important?
If you go on the free version of ChatGPT and ask it to write an article about something that happened way past its training data (2022 as of this writing), you would not get an accurate response. It would probably "hallucinate" and give you incorrect information.
Let me give you an example:
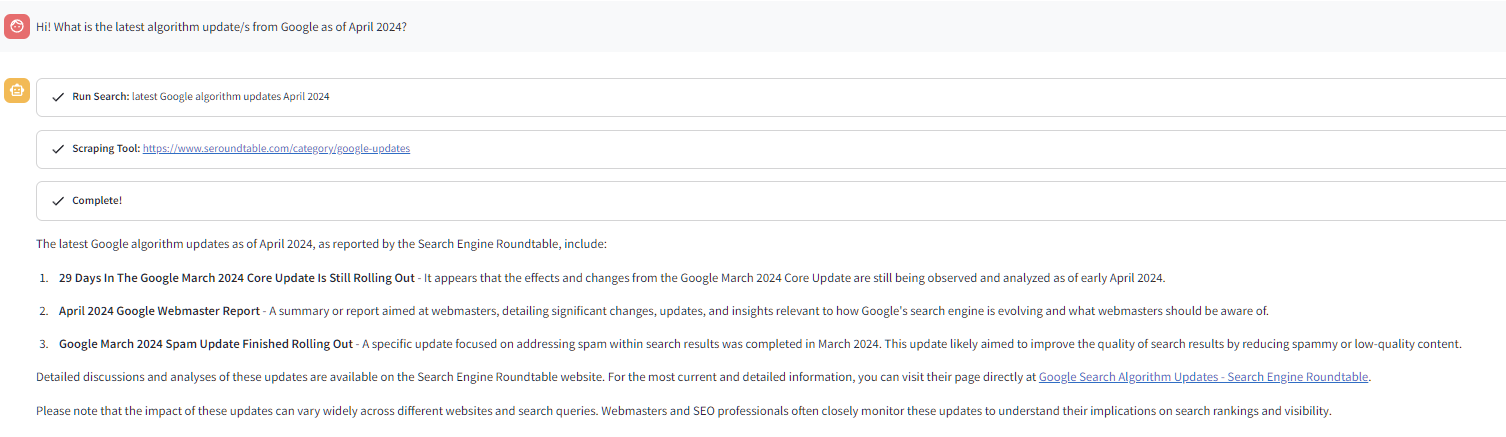
Notice the difference?
You can see two different steps that the model had to take in the Streamlit app before it provided an answer:
- Run Search - this is the custom function I made for it to be able to browse SERPs first and get a list of links
- Scraping Tool - as the name suggests, it scrapes the links from Run Search so it can "read" and update its context about the topic
With just these two additional functions, I was able to generate drafts with updated information for my experimental sites. I still had to edit them a bit in terms of the subheadings it used (it loved using "Introduction" and "Conclusion" even if I explicitly tell it not to) as well as formatting it on Wordpress.
Experimental Site # 1
I am not going to reveal the domain names of my experimental websites since I learned from Twitter/X folks to "build in secret". I also don't want any of these sites to be nuked.
The first experimental site that I did was actually dormant for about 4-5 years. I bought the domain and just placed a Wordpress blog installation. I would be lucky enough to write 1-3 posts a year before.
With my draft generator, I was able to quickly create and publish 1-3 posts within an hour or two. This first experimental site depended on certain trends, so it's not like I could create posts every day.
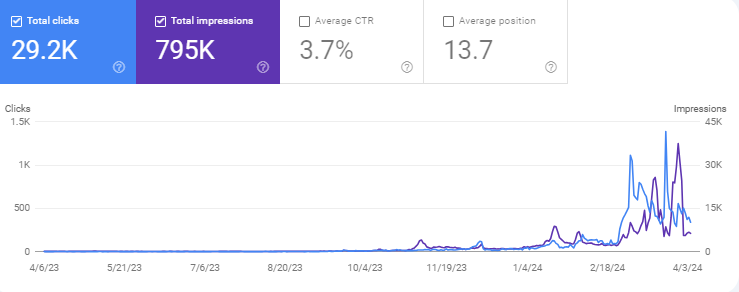
I started "regularly" posting late last year and it just so happens that there are 1-2 posts every month that were able to net more clicks than the usual. As I've said, these are very trend-dependent.
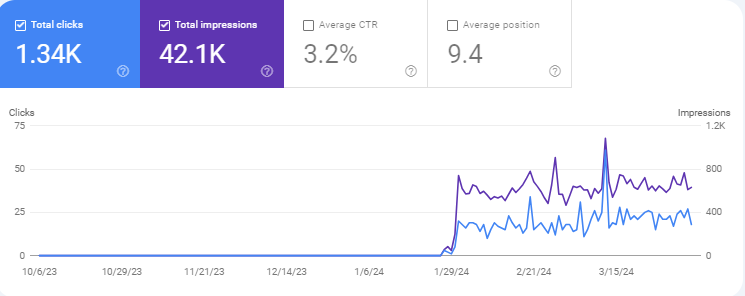
I was still able to create evergreen posts for this site. This is one example. It was able to rank because of its domain age and topical authority. I had to ask my Streamlit app to create this longform evergreen article piece by piece.
Experimental Site # 2
For my second experimental site, I was able to buy an expired domain with a DA of about 20 when I bought it 2 years ago.
I actually started with a couple of GPT-2 models here before, but it wasn't working so I stopped. I then just started to write whenever I had free time (lol). It was able to net several press release requests, so it was still able to bring in a bit of change money.
I also applied the same generative AI things as the first experimental site. I used it to create drafts for some trending topics, but I also created more evergreen posts for a particular niche as well.
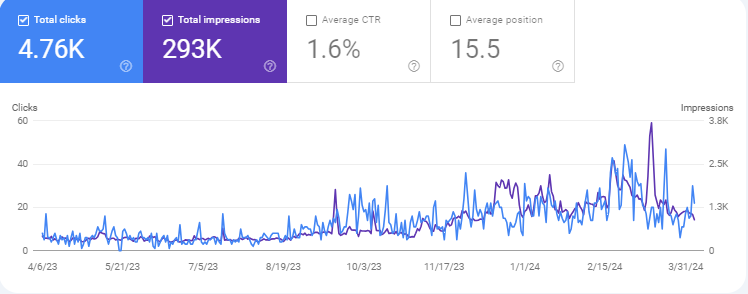
It isn't as erratic or volatile as experimental site # 1 due to the difference in the niche. It slowly grew more but it considerably has less traffic compared to #1
I also did something different for experimental site # 2. I was exploring open source LLMs. I was curious if they were able to generate drafts on the same league as OpenAI's models.
Short answer is yes, they can but it takes a bit more work. Either you have to have a powerful rig (I am still rocking an RTX 3080) or you find some other cloud provider that hosts endpoints for these open source models.
I was able to run smaller LLMs such as Microsoft's Phi-2, but it sucked. I tried Mixtral 7b, but it was slow. I also tried Mixtral's 8x7b MoE model, but that was even slower. I didn't have enough RAM to run them as fast as I wanted (8x7b quantized needs at least 28gb if I remember correctly).
So how was I able to still use the open source LLMs without hosting it locally? Enter TogetherAI. They host several open source LLMs that are as almost as good as OpenAI's GPT-3.5 model.
I was able to test out several models but I focused on several that worked the best for my use case: Nous Hermes's Mixtral models, OpenChat 3.5, and the Qwen models.
I used the same prompt templates and it did provide usable drafts. They were also substantially cheaper than even OpenAI's 3.5.
You could consume 1M tokens at less than $1 on TogetherAI. OpenAI charges $1.50 / million tokens output for 3.5, and $30 / million output tokens for GPT-4-turbo.
Bulk Generation and Posting Experiment
I made another Streamlit app that was able to generate more than one draft at a time. All it needed was a list of keywords. I was curious if it really did work since a lot of the Twitter/X techfluencers flaunted their products that were able to do that. I didn't want to subscribe and buy so I tried building my own.
I tried generating about 50 evergreen posts for a section in experimental site #2. No edits. No internal links. What happened?
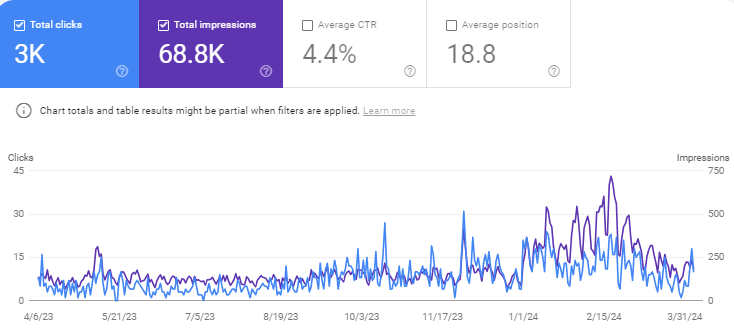
Nothing significant happened. This is important. Read again: Nothing significant happened.
I expected traffic to drop or maybe even penalized since I published the posts right before the March 2024 spam update rolled out. Nothing happened.
Experimental site #2 still continues to get clicks and impressions for pages that it was already ranking before. There is even a miniscule number of clicks for the purely AI-generated content I bulk published. It's small but it is there.
What does the result tell us?
Why am I telling you this? Do I want you to just use AI to populate your blog or website?
I am basically telling you that Google doesn't seem to know how to handle the ongoing influx of garbage AI posts on the internet. With just a little bit of editing (and maybe even more prompt engineering) you can get away with a lot, and I see this as a potential problem.
As someone with no prior software engineering or developing experience, I was able to create these tools. I'm sure someone else has a better version of this, running locally on their machine. If I can make and run these experiments, so can a lot of other more qualified people.
For SEO, it is not enough to produce high-quality content anymore. You need to do it at scale. This is something I have been trying to push for: use generative AI as a tool to multiply your efforts.
A lot of people are still afraid to use it or maybe they just outright hate it because it can replace their jobs. If you aren't using it even just to check your grammar or to find synonyms, you are already 10 steps behind.
Generative AI should now be a part of your process. We all know Google likes larger websites with longer content; and this is just one part of the SEO puzzle.
Tech SEO is now more important than ever
With everyone else basically pushing out content seemingly every hour or so, the weight of the other SEO "factors" could shift.
I'm talking about tech SEO. If anyone can now produce content at scale, what's the next best thing?: Making sure your large website runs well.
The next problem that these AI garbage peddlers ran into was getting the 100s or 1000s of pages indexed in a day or two. That is troublesome since Google needs to be able to crawl all of those pages before indexing. It can take months.
After that, Google needs to be able to understand the relationship across all of these pages. They need to load fast. Crawling problems need to be as close to zero as possible.
All of those things currently cannot be addressed by generative AI; at least not in a cheap way. It is now needed more than ever to check under the hood and make sure everything runs alright.
What did I learn after all of this?
I would just try to list everything down here and hope everything still makes sense:
- Adding updated information to your prompts can work wonders for generating articles and drafts.
- The magic is really in customizing your tools to fit what you need. If everyone else has the same platform, the results will be just wildly similar.
- A little bit of editing and customizing can go a long way.
- Google sucks at detecting AI-generated articles except for the blatantly-obvious ones.
- Open source LLMs are way cheaper and can give you a chance to scale with a smaller budget.
- AI garbage can rank and get traffic..at least for now.
- Tech SEO will have more weight now that everyone else can scale up their content game with generative AI.